Overfitting & Underfitting
In statistics, goodness of fit refers to how closely a model’s predicted values match the observed (true) values.
A model that has learned the noise instead of the signal is considered “overfit” because it fits the training dataset but has poor fit with new datasets
We can understand overfitting better by looking at the opposite problem, underfitting.
Underfitting occurs when a model is too simple – informed by too few features or regularized too much – which makes it inflexible in learning from the dataset.
Simple learners tend to have less variance in their predictions but more bias towards wrong outcomes (see: The Bias-Variance Tradeoff).
On the other hand, complex learners tend to have more variance in their predictions.
How to Detect Overfitting in Machine Learning
A key challenge with overfitting, and with machine learning in general, is that we can’t know how well our model will perform on new data until we actually test it.
To address this, we can split our initial dataset into separate training and test subsets.
This method can approximate of how well our model will perform on new data.
If our model does much better on the training set than on the test set, then we’re likely overfitting.
For example, it would be a big red flag if our model saw 99% accuracy on the training set but only 55% accuracy on the test set.
If you’d like to see how this works in Python, we have a full tutorial for machine learning using Scikit-Learn.
Another tip is to start with a very simple model to serve as a benchmark.
Then, as you try more complex algorithms, you’ll have a reference point to see if the additional complexity is worth it.
This is the Occam’s razor test. If two models have comparable performance, then you should usually pick the simpler one.
How to Prevent Overfitting in Machine Learning
Detecting overfitting is useful, but it doesn’t solve the problem. Fortunately, you have several options to try.
Here are a few of the most popular solutions for overfitting:
Early stopping
When you’re training a learning algorithm iteratively, you can measure how well each iteration of the model performs.
Up until a certain number of iterations, new iterations improve the model. After that point, however, the model’s ability to generalize can weaken as it begins to overfit the training data.
Early stopping refers stopping the training process before the learner passes that point.
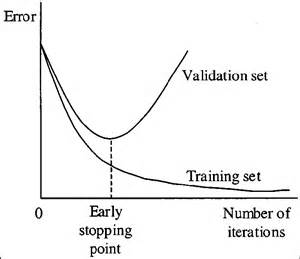
Today, this technique is mostly used in deep learning while other techniques (e.g. regularization) are preferred for classical machine learning.
Regularization
Regularization refers to a broad range of techniques for artificially forcing your model to be simpler.
The method will depend on the type of learner you’re using. For example, you could prune a decision tree, use dropout on a neural network, or add a penalty parameter to the cost function in regression.
Oftentimes, the regularization method is a hyperparameter as well, which means it can be tuned through cross-validation.
Batch Normalization reduces overfitting because it has a slight regularization effects. Similar to dropout, it adds some noise to each hidden layer’s activations. Therefore, if we use batch normalization, we will use less dropout, which is a good thing because we are not going to lose a lot of information. However, we should not depend only on batch normalization for regularization; we should better use it together with dropout.
.
